A kernel-bypass OS scheduler designed to minimize tail latency for applications executing at microsecond-scale and exhibiting wide service time distributions
核心思想是 Dynamic Application-aware Reserved Cores (DARC), 感知应用处理时间,为具有短处理时间的请求预留核。
Background and Motivation
$\bullet$ 现有CPU scheduling策略在heavy-tailed workload下的不足
这里说的CPU scheduling是指请求到达时,如何调度给每个核(负载均衡)
问题:dispersion-based head-of-line blocking. 大请求阻塞了小请求(即使队列长度很短)
d-FCFS:每个worker有local queue,分配平均的请求
c-FCFS:一个queue负责接收所有请求,然后dispath给idle的worker
TS:不同请求种类有不同的queue, 可preemption(Shinjuku)
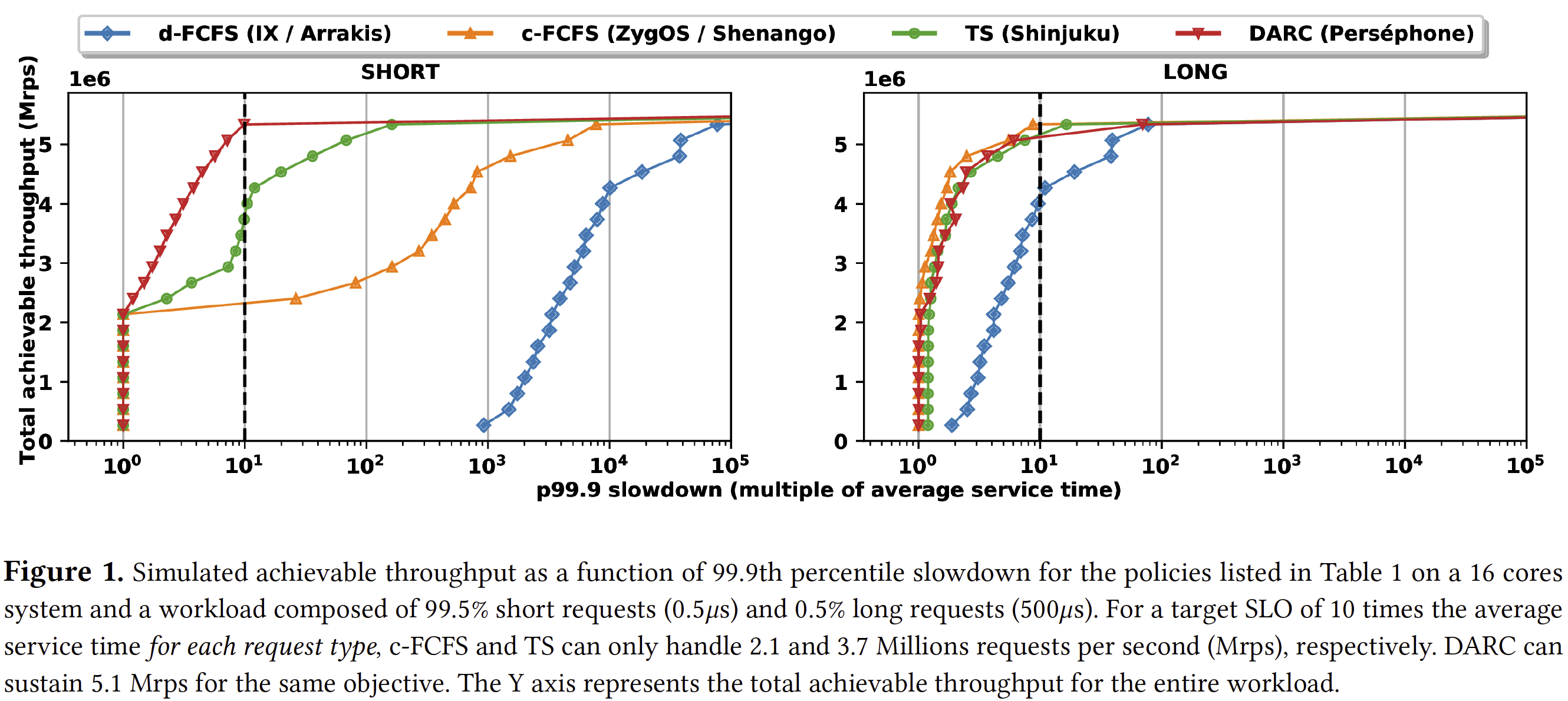
Shinjuku’s TS policy fares better than c-FCFS and d-FCFS, being both work conserving and able to preempt long requests: it maintains slowdown below 10 up to 3.7 Mrps, 70% of the peak load. However, this simulation accounts for an optimistic 1$\mu$s preemption overhead and overlooks the practicality of supporting preemption at the microsecond scale.
$\bullet$ Insight
Leaving certain cores idle for readily handling potential future (bursts of) short requests is highly beneficial at microsecond scale
本质上,work preemption是最优的,但是在微秒级下interrupt的开销太大,所以Perséphone思想是通过利用请求的大小特征,不采用preemption的方式,实现近似最优的效果。
Theory tells us that heavy-tailed workloads do best in terms of tail latency under processor sharing (PS) (Shinjuku paper).
Instead, given an understanding of each request’s potential processing time, an application aware, not work conserving policy can reduce slowdown for short requests by estimating their CPU demand and dedicating workers to them. These workers will beidlein the absence of short requests, but when they do, they are guaranteed to not be blocked behind long requests.
$\bullet$ 总结
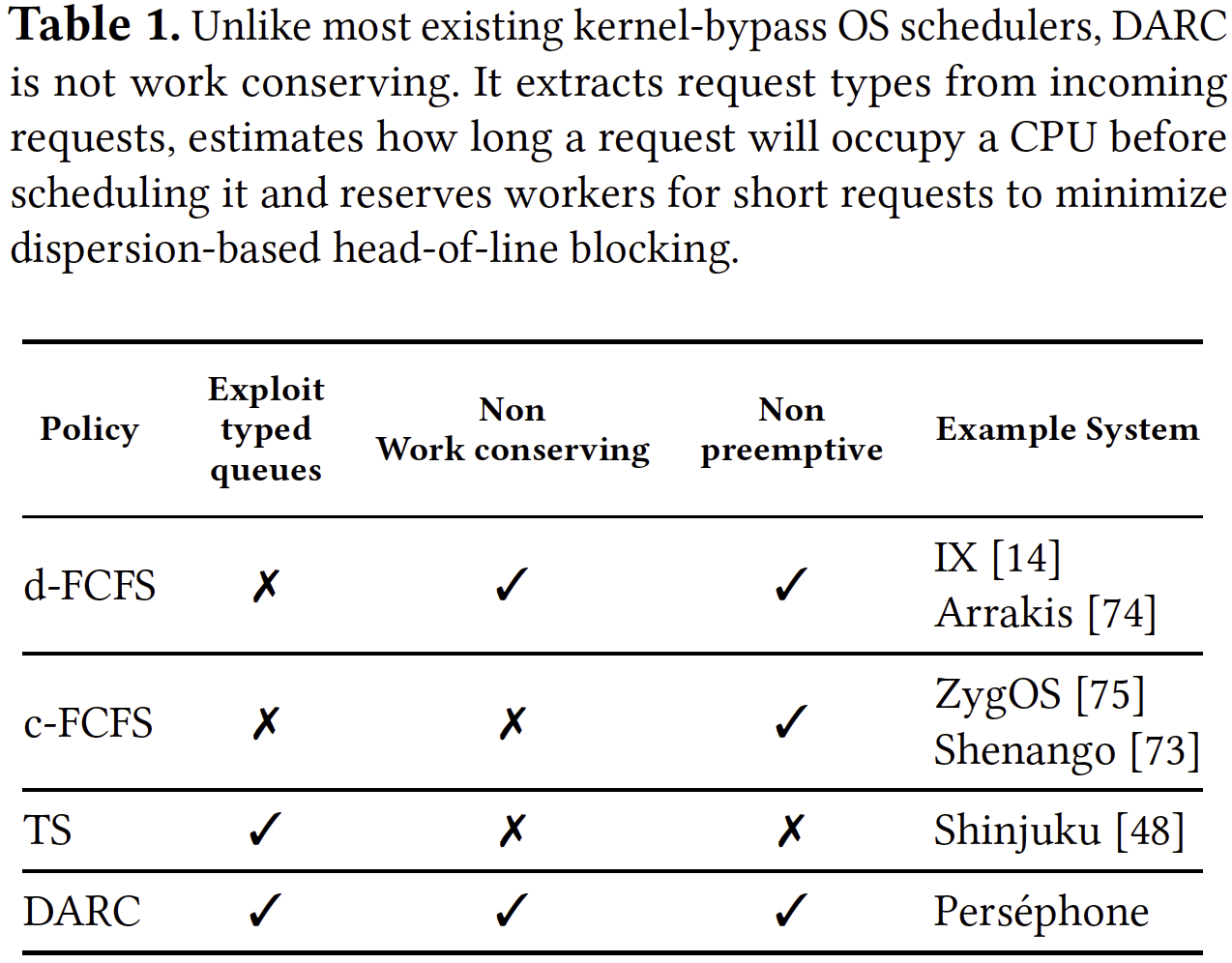
Design
需要解决两个问题:
(1) 预测每个请求的CPU需求: a request classifiers API for capturing request types. Profiling the workload and updating reservations.
(2) Partition CPU resources among types while retaining the ability to handle bursts of arrivals and minimizing CPU waste
注意其实涉及到了两个层面的策略:一方面是请求如何调度到已分配的核上;另一方面是如何给每种type分配合适的核数量
$\bullet$ Scheduling model
A single queue abstraction to application workers: it iterates over typed queues sorted by average service time and dequeues them in a first come, first served fashion. For each request type registered in the system, if there is a pending request in that type’s queue, DARC greedily searches the list of reserved workers for an idle worker. If none is found, DARC searches for a stealable worker
$\bullet$ DARC reservation mechanism
根据请求种类的average CPU demand 分配 worker.
计算Average CPU demand(runtime更新): using the workload’s composition, normalizing the contribution of each request type’s average service time to the entire workload’s average service time. The contribution of a given request type is its average service time multiplied by its occurrence ratio as a percentage of the entire workload.

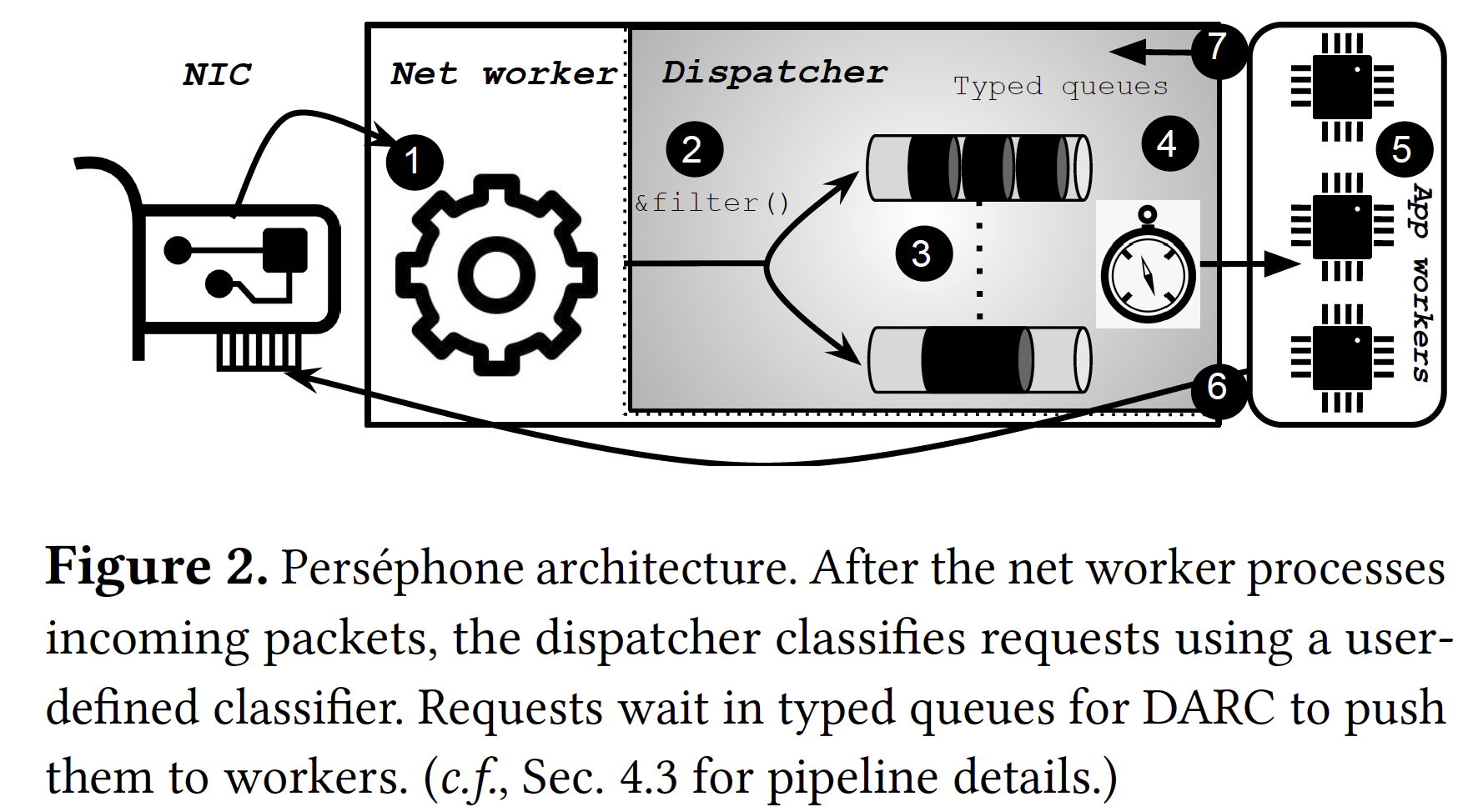
$\bullet$ 系统架构
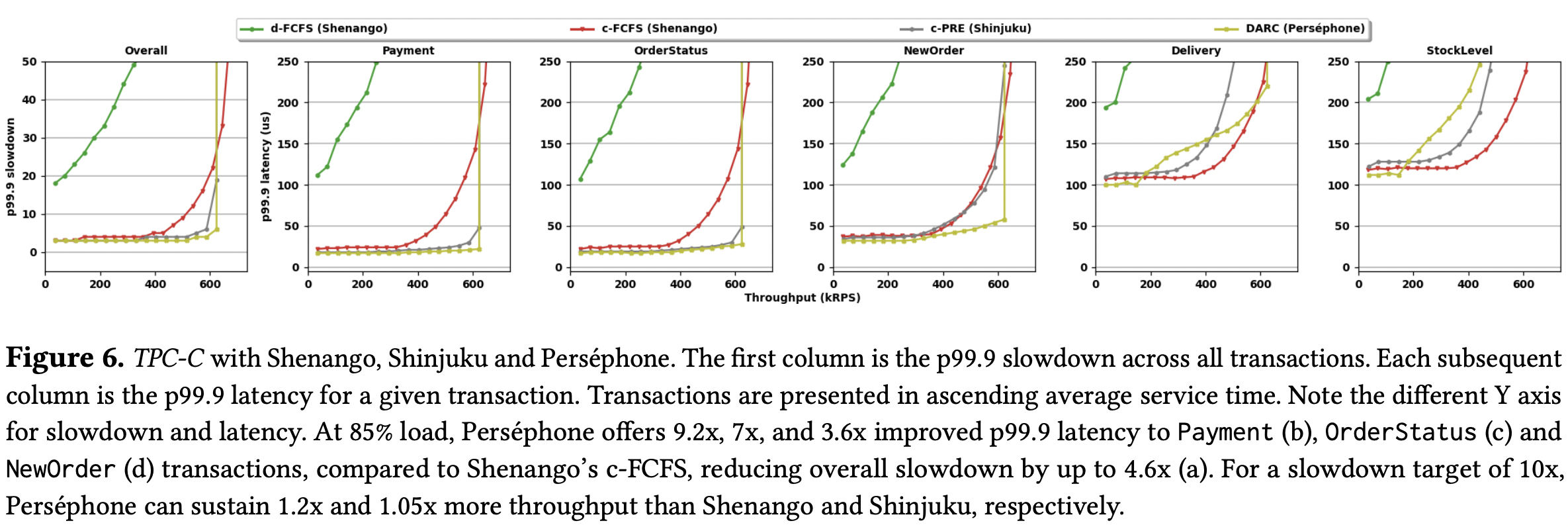
Evaluation

Thinking
Perséphone借鉴了网络流调度中短流优先(SJF/SRPT)的思想
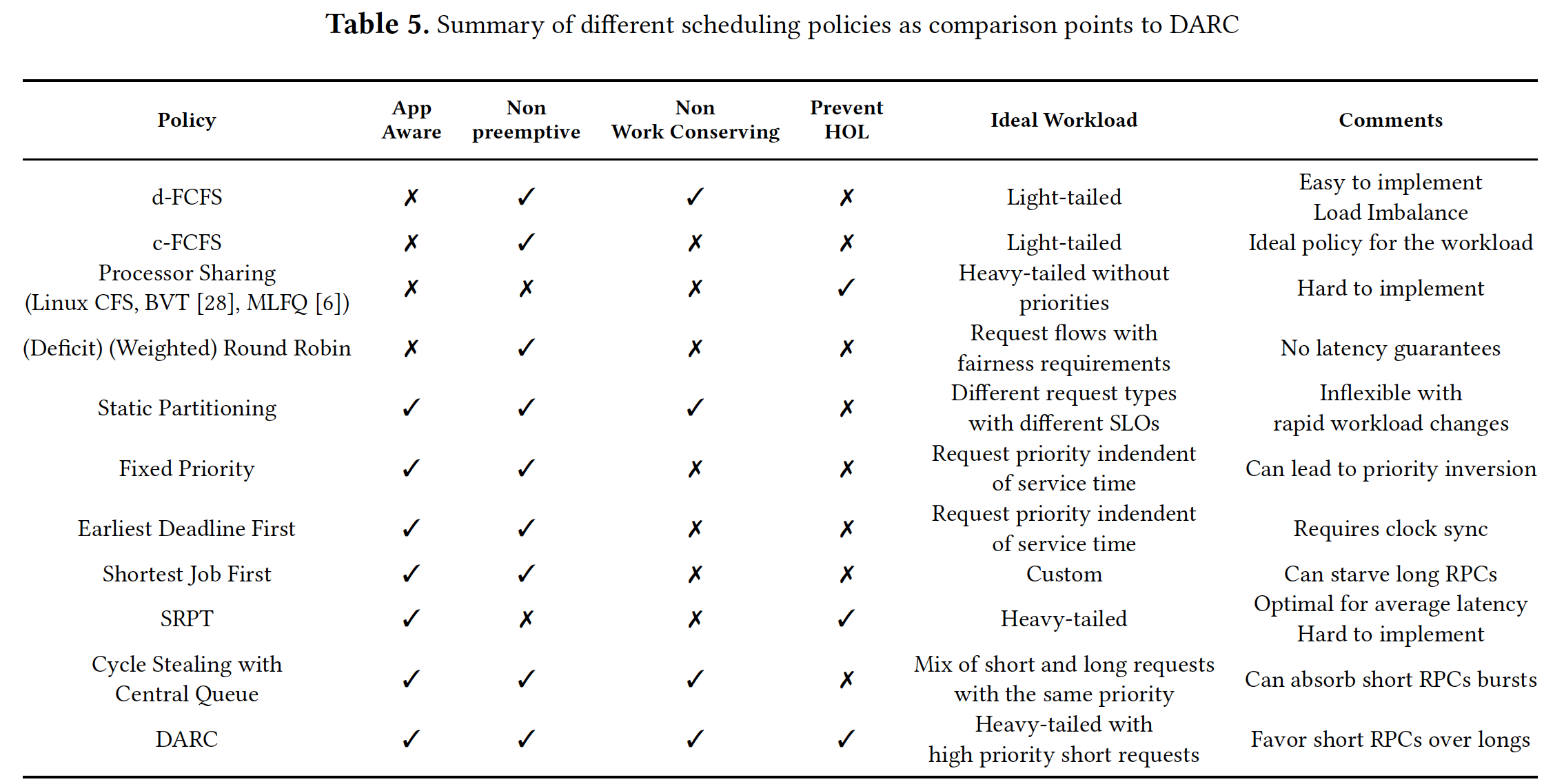
比较全面的总结:
参考文献
When Idling is Ideal: Optimizing Tail-Latency for Heavy-Tailed Datacenter Workloads with Perséphone