在微秒级应用请求的背景下,深入研究负载均衡策略以及核分配策略对latency、CPU efficiency的影响
What load-balancing and core-allocation policies yield the best combination of latency (median and tail) and CPU efficiency for microsecond-scale tasks?
Background and Motivation
-
负载均衡策略:每个请求到达时,调度到哪个核(across cores within an application)
Single queue: 将所有task放在一个共享队列中
Enqueue choice: enqueue a task to the less-loaded of two randomly sampled cores
Work stealing: 当一个核空闲时,steal当前有任务排队的核(steal half)
Work shedding: overloaded cores shed load to other cores;request other cores take some of their load -
核分配策略:每个应用应该分配多少核
Static: 每个应用被分配的核数不变.需要预先考虑峰值任务量来分配核数.
Per-task: 每当一个task到达时即分配一个核. 会有每task的和分配开销.
Queueing-based: 当检测到有排队时新分配一个核.
CPU utilization-based: 基于空闲的核数或者fraction of time cores spend working on tasks
Failure to find work: yield a core when the core is unable to find any tasks to work on -
各种策略的系统开销(微秒级task下不能忽视)
At a bare minimum, reallocating a core requires an inter-processor interrupt (IPI) from the core that makes the reallocation decision to the core that will be reallocated to a different application; this takes about 1993 cycles or roughly 1 $\mu$s.
Because load balancing requires communication between cores, its overhead arises primarily from cache misses while retrieving cache lines from the L2 cache of another core.
Simulation Study
先统一采用静态核分配策略, 测试各个负载均衡策略的性能; 再在动态核分配策略下, 观察各个负载均衡策略的性能, 同时观察比较不同的核分配策略(相同负载均衡策略下).
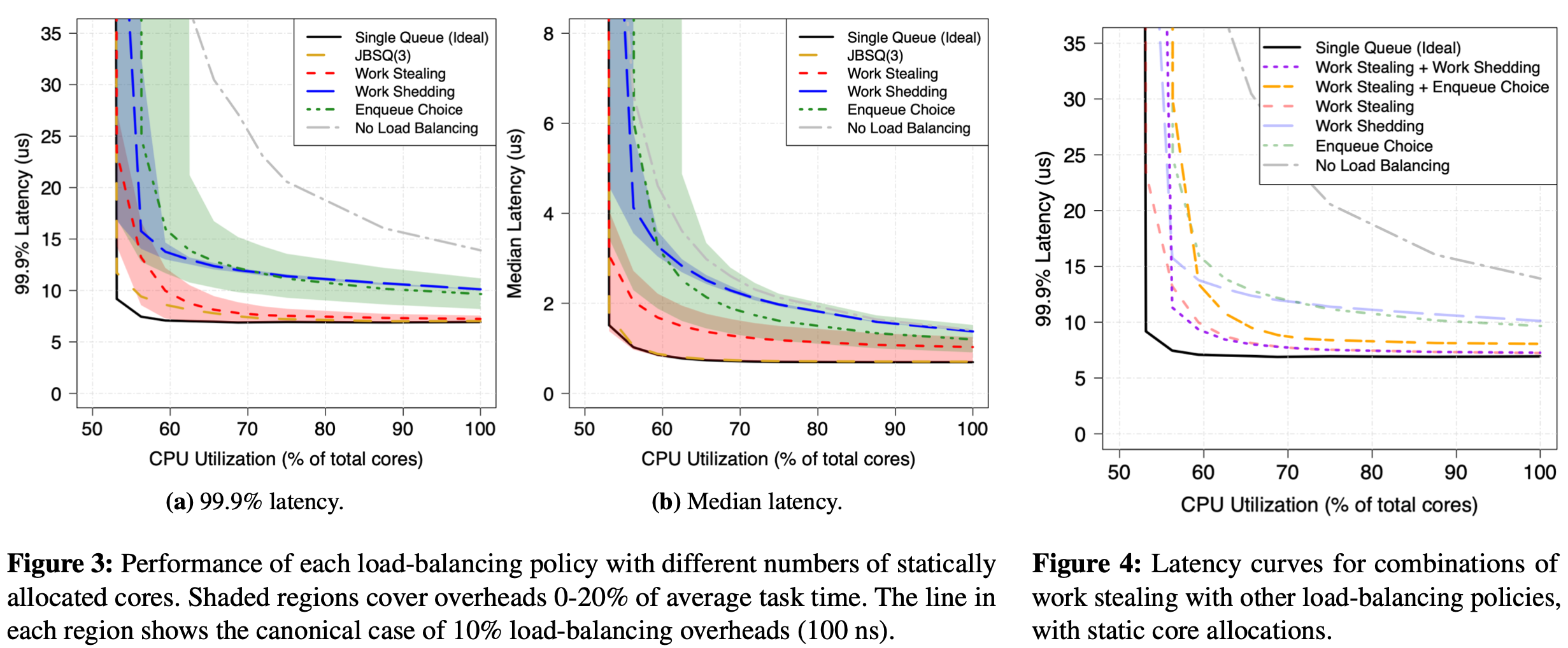
-
Finding 1: With static core allocations, work stealing achieves better latency (at the median and tail) for a given efficiency (number of allocated cores) than work shedding or enqueue choice.
-
Finding 2: With static core allocations, adding shedding on top of work stealing provides some latency benefit (primarily at the tail) while adding enqueue choice to work stealing makes performance unchanged or worse.
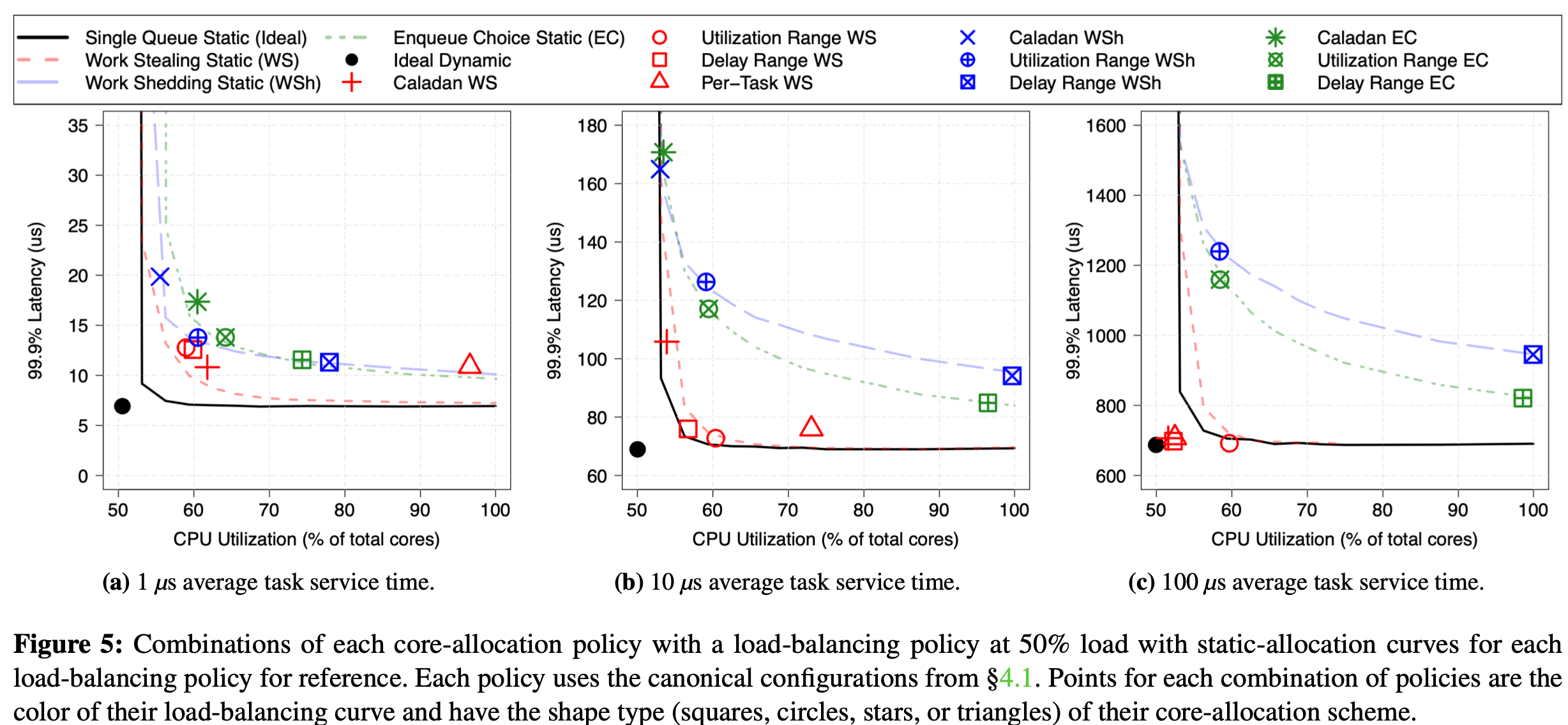
-
Finding 3: When cores are dynamically reallocated, work stealing performs better than shedding or enqueue choice. This is robust against all factors mentioned in Finding 1.
-
Finding 4: For short tasks, none of the core-allocation policies we tried achieved better latency (median or tail) for a given average efficiency than static core allocations (with the same load-balancing policy). However, this becomes possible with longer tasks.
对于微秒级task来说 动态的核分配策略的增益可能被其overhead抵消, 不如静态核分配策略
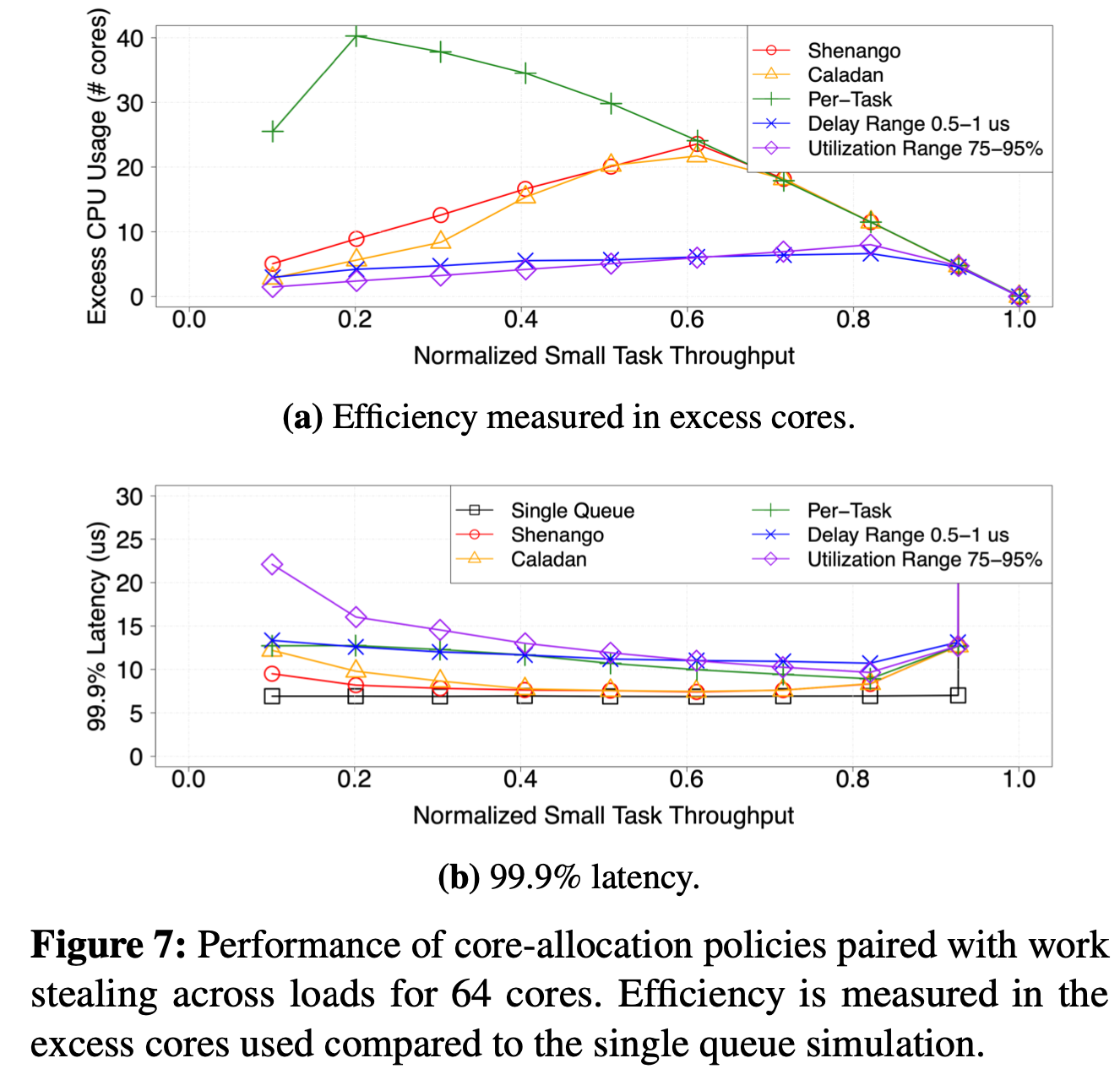
-
Finding 5: Policies that explicitly optimize for an end-to-end user-visible metric (e.g., delay range and utilization range) have more consistent performance, as measured by those metrics, across different configurations.
-
Finding 6: Yielding cores only when no work is found (when there is no queued work or work stealing fails) makes it challenging to achieve good efficiency with small tasks, especially with many cores.
总结:微秒级task下, work-stealing 是最好的负载均衡策略, 基于delay或utilization的核分配策略性能最好(具体是哪个取决于关注的metric)
Evaluation
使用delay range or utilization range的策略优化Caladan
Thinking
- 这篇文章通过合理抽象系统中的基本结构和要素,借助仿真实验得到一系列结论,非常经典的系统领域的研究方法(这篇文章的风格是笔者非常喜欢的~)
-
几篇文章(相同或者同一个group的作者:Amy Ousterhout;Joshua Fried;Adam Belay,MIT CSAIL)的研究脉络:Shenango(NSDI’19) -> Caladan(OSDI’20) -> Breakwater(OSDI’20) -> Perséphone(OSDI’21) -> SchedulePolicy(NSDI’22)
均关注microsecond-scale tasks:
Shenango: 首次提出使用细粒度的$\mu$s级调度实现CPU高efficiency, 负载均衡使用work stealing, 核分配根据queueing delay
Caladan: 在 Shenango 基础之上,考虑资源竞争,实现更好QoS的 CPU scheduler
Breakwater: 基于Shenango/Caladan系统,做服务器端 RPC overload control
Perséphone: Dynamic Application-aware Reserved Cores (DARC), 感知应用处理时间,为具有短处理时间的请求预留核, 避免用preemption
SchedulePolicy: 在微秒级请求的背景下,深入研究负载均衡策略以及核分配策略对latency、CPU efficiency的影响