1. Understanding Host Interconnect Congestion
揭示了Google实际生产集群中主机拥塞的原因:高带宽访问链路导致主机互连(NIC 到 CPU 数据路径)出现瓶颈。
Host congestion turns out to be a result of imperfect interaction (and resource imbalance!) between multiple components within the host interconnect
主机拥塞丢包:
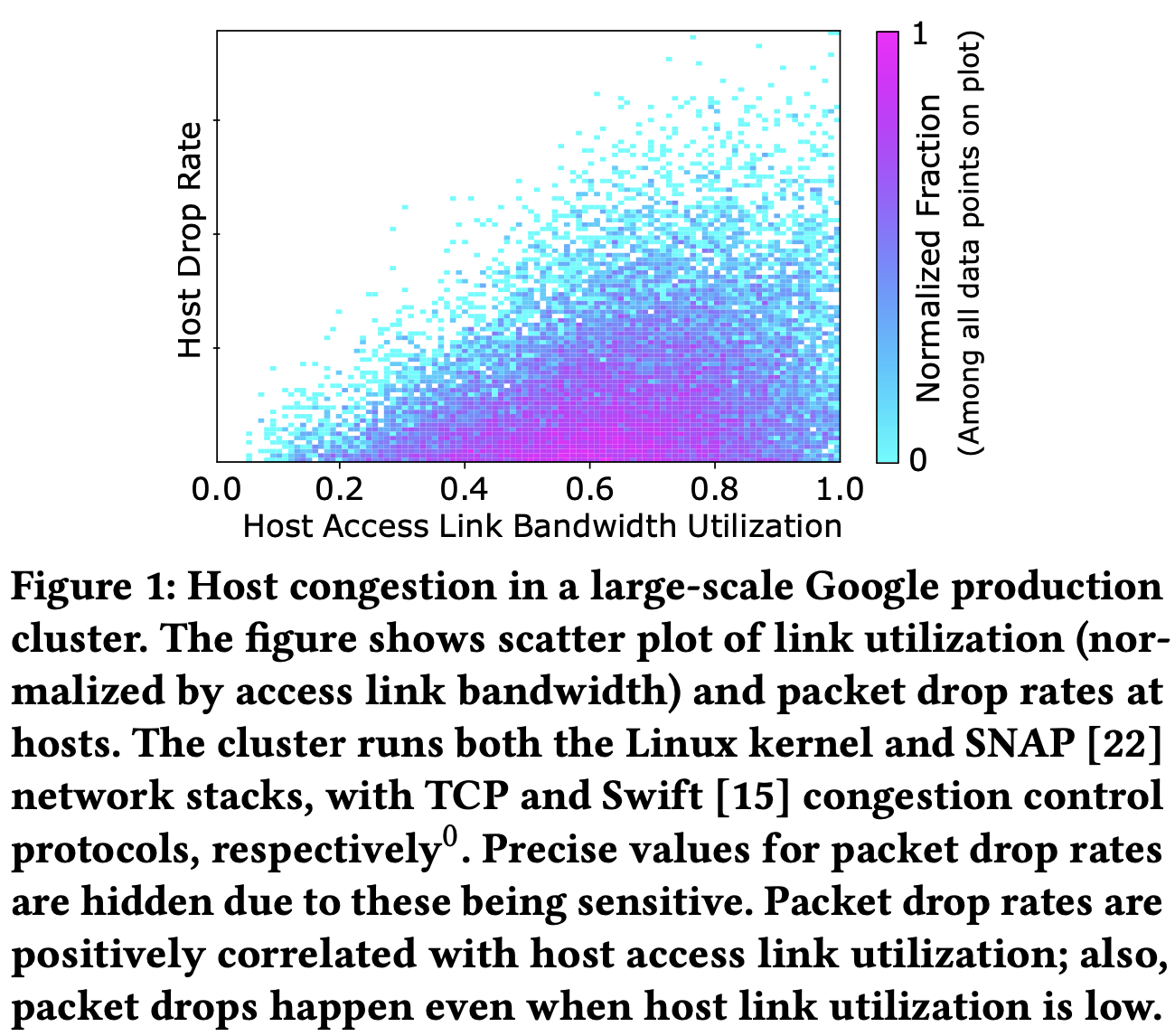
接收端datapath:
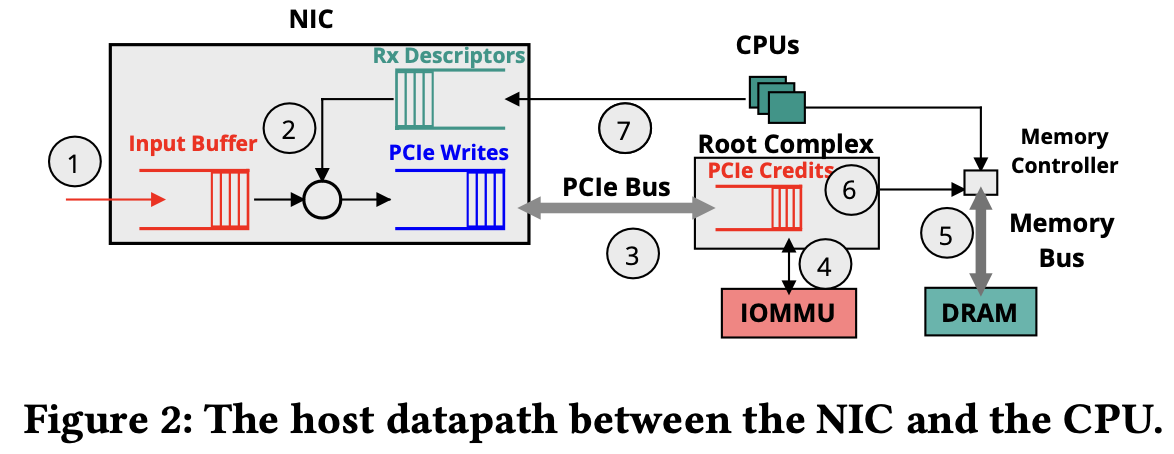
host congestion 两大核心原因:
- IOMMU induced congestion: every DMA request initiated by the NIC, one must translate the NIC-visible virtual address to host physical address; when the address translation (page) table does not fit into the cache, one or more memory accesses are required for the translation. The resulting increase in per-DMA latency directly impacts the rate at which NIC can transfer data to CPU.
- Memory bus induced congestion: CPUs reading/writing data to main memory share the memory bus bandwidth with the NIC performing DMA operations; when memory bus is contended, CPUs are able to acquire a larger fraction of memory bus bandwidth than NIC. As a result, in-flight packets result in NIC buffers building up before congestion control protocols can react
Note: 实验中发现Swift也起了作用,但是因为host delay 阈值设置为100us, NIC buffer size 为1MB, 只有当队列积累到一定程度swift才起作用,并且行为展现为典型的锯齿型
Technology trends suggest that the problem of host congestion is only going to get worse with time. As discussed earlier, while host access link bandwidths are likely to increase by 10× over the next few years, technology trends for essentially all other host resources—e.g., NIC buffer sizes, the ratio of access link bandwidth to PCIe bandwidth, IOTLB sizes, memory access latencies, and memory bandwidth per core are largely stagnant.
解决思路:
- Rethinking host architecture for future-generation datacenter networks;
- Rethinking congestion signals:CC 考虑主机内的信号,如CPU utilization, memory bandwidth contention, memory fragmentation等
- Rethinking congestion response:计算资源、内存资源、网络带宽资源都需要分配,传统CC只是通过减速来调整网络带宽资源分配。需要一种更加协调一致分配多种资源的方法,以及考虑host congestion的响应时间尺度。
2. Congestion Control in Machine Learning Clusters
这篇论文发现一个有意思的现象:传统拥塞控制追求的公平性对于ML工作负载可能不友好,不公平的CC反而可以加速ML工作负载。
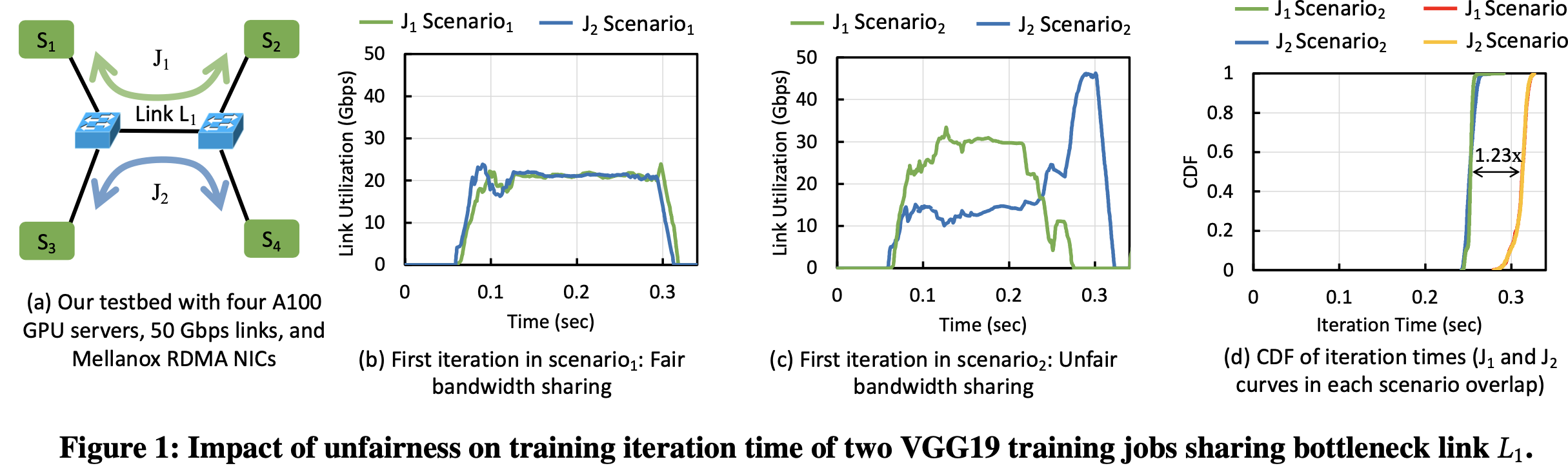
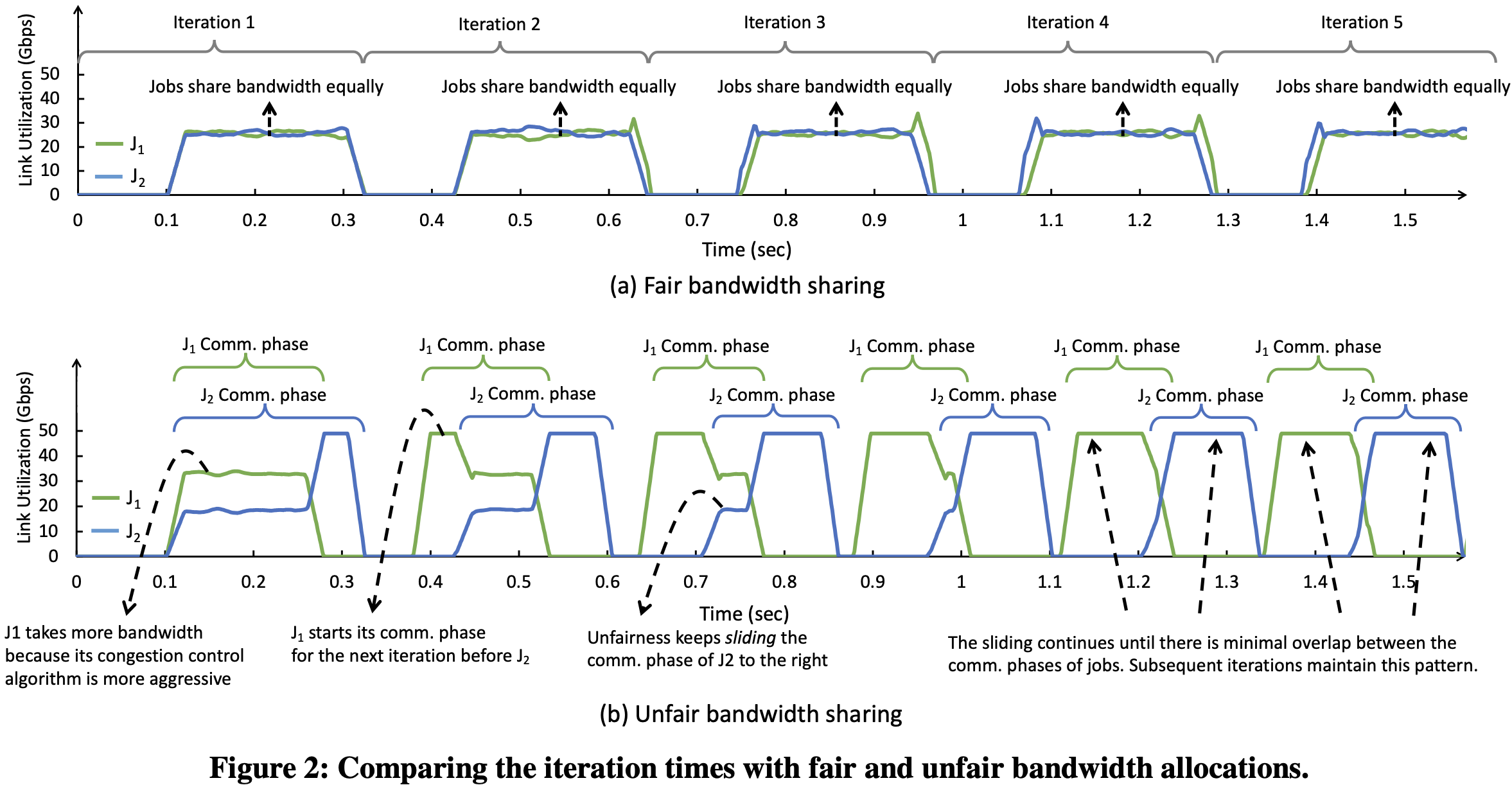
原因: DNN训练具有ON-OFF特征,即计算-通信-计算-通信-….. 不公平性实际上可以将不同作业的计算和通信阶段交替穿插在一起,使它们能够一次性独占网络带宽,从而提高所有竞争作业的训练时间。这一类作业被称作compatible,如下图(b),最终两个作业计算和通信的重叠越来越小
如何判断compatible: 建立了几何抽象,圆圈周长代表interation time(一轮computation time + communication time). 为了避免拥塞,旋转圆圈以找到通信所占的弧不碰撞的位置,如果找到这样的轮换,则两个作业是兼容的。此外,重叠每个作业(未着色区域)的计算时间是可以接受的,因为假设作业之间不共享计算资源。如果两个作业interation time不同,取二者最小公倍数
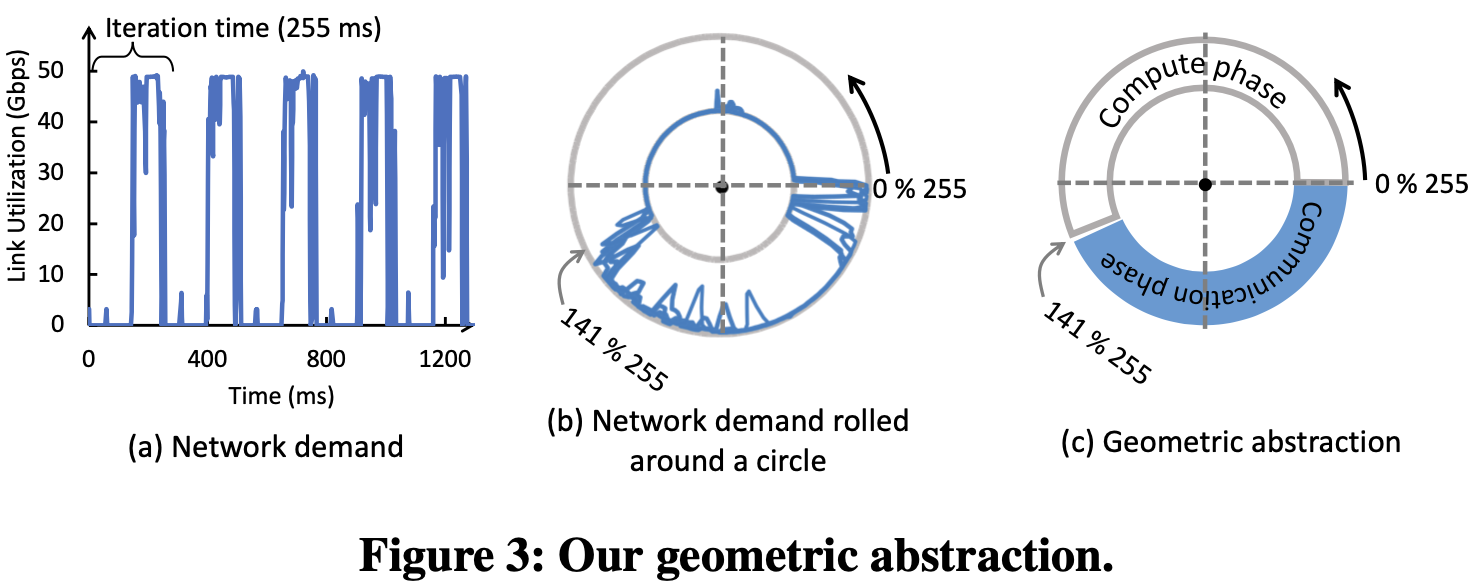
如何在部署中引入不公平性以降低网络拥塞对ML作业的影响:
- 使用不公平的传输控制协议:对compatible的作业使用不公平的拥塞控制算法,例如调整DCQCN中$R_{AI}$参数,a job closer to completing its communication phase is more aggressive than a job just about to start its communication
- 利用优先级队列:每个作业赋予优先级,缺点是交换机队列有限
- 流调度:根据算出的作业是否compatible信息,使用集中式控制器显式控制作业通信阶段的开始,但是需要在cluster范围工作,具有全局高精度时钟
3. Sidecar: In-Network Performance Enhancements in the Age of Paranoid Transport Protocols
参考文献
Understanding Host Interconnect Congestion
Congestion Control in Machine Learning Clusters
Sidecar: In-Network Performance Enhancements in the Age of Paranoid Transport Protocols
Towards Dual-band Reconfigurable Metamaterial Surfaces for Satellite Networking