第一个为基于任务的分布式系统提供有效的 Collective Communication 支持的工作。
Background
-
Task-based distributed systems
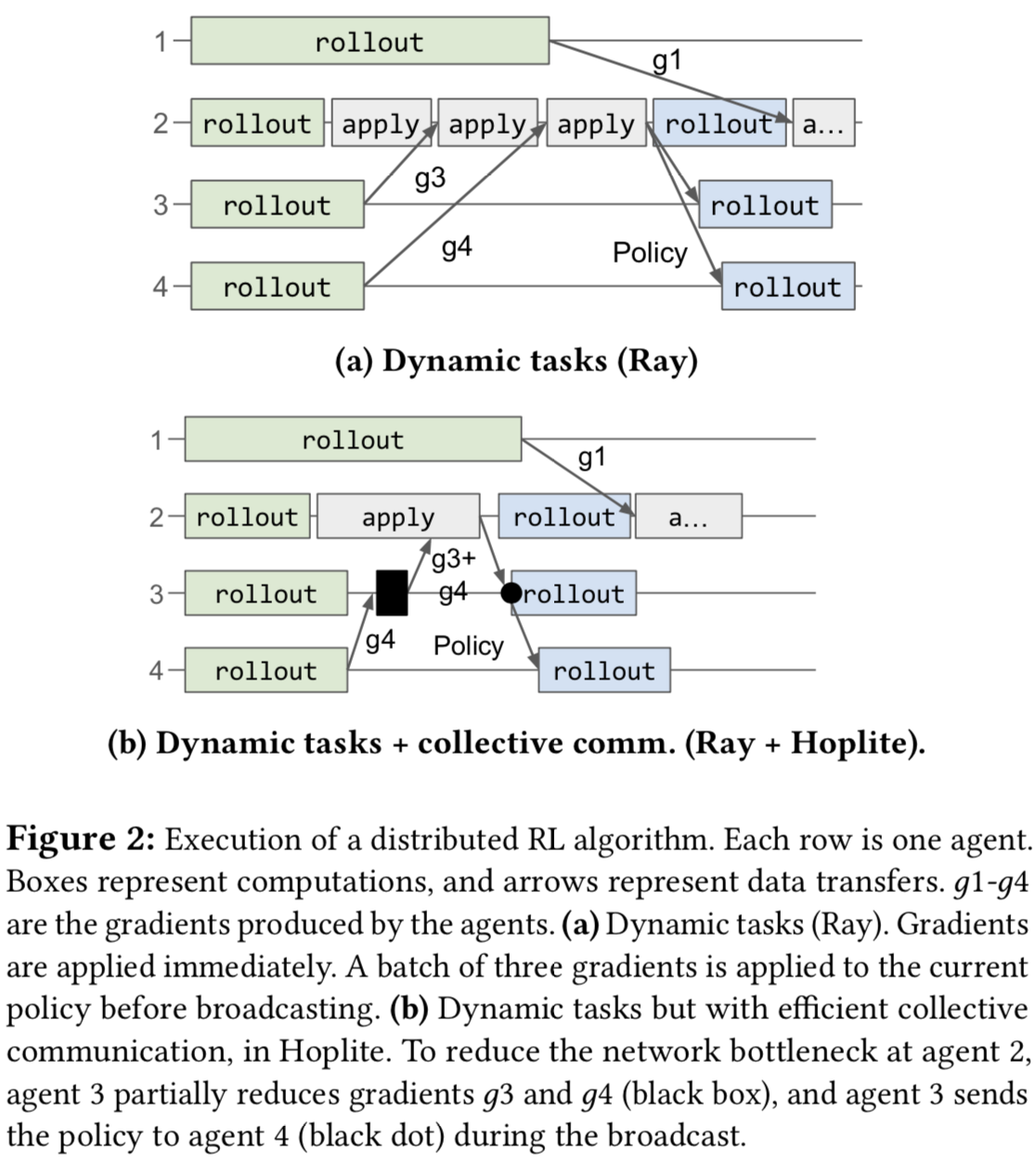
asynchronous and dynamic computation: a caller can dynamically invoke a task 𝐴, which immediately returns an object future, i.e. a reference to the eventual return value. By passing the future as an argument, the caller can specify another task 𝐵 that uses the return value of 𝐴 even before 𝐴 finishes. The task-based system is responsible for scheduling workers to execute tasks 𝐴 and 𝐵 and transferring the result of 𝐴 to 𝐵 between the corresponding workers.
-
Collective Communications
e.g., broadcast, reduce
现有的collective communication library: OpenMPI, MPICH, Horovod, Gloo, and NCCL.
Motivation
-
现有的collective communication library的问题
-
The communication pattern has to be statically defined before runtime. 只对具有bulk-synchronous parallel 模型的应用友好。例如:all the workers compute on their partitioned set of training data and synchronize the model parameters using allreduce.
-
容错性不佳. When any worker fails, all the workers participating in the collective communication hang, and applications are responsible for fault tolerance: checkpointing the entire application periodically (e.g., per-hour), and when a process fails, the entire application rolls back to a checkpoint and re-execute.
-
Goal: Bring the efficiency of collective communication to dynamic and asynchronous task-based applications.
-
A collective communication layer for a task-based system should adjust data transfer schedule at runtime based on task and object arrivals. -
A collective communication layer for task-based systems has to be fault-tolerant: allowing well-behaving tasks to make progress when a task fails and allowing the failed task to rejoin the collective communication after recovery.
Design
核心设计两点:
- decentralized fault-tolerant coordination of data transfer for reduce and broadcast
- pipelining of object transfers both across nodes and between tasks and the object store.
Hoplite Workflow
Object Directory Service
个人认为这个 object store 的引入是实现 runtime schedule 的关键
Pipelining
对 object store 读取数据的优化:Hoplite uses pipelining to achieve low-latency transfer between processes and across nodes for large objects. This is implemented by enabling a receiver node to fetch an object that is incomplete in a source node.
Receiver-Driven Collective Communication
Broadcast的优化:If all receivers simply fetch the object from the sender, the performance will be restricted by the sender’s upstream bandwidth. Traditional collective communication libraries can generate a static tree where the root is the sender node to mitigate the throughput bottleneck. Hoplite’s receiver-driven coordination scheme is to achieve a similar effect but using decentralized protocols: use receivers who receives the object earlier than the rest as intermediates to construct a broadcast tree.
Reduce更复杂:Broadcast is simpler because a receiver can fetch the object from any sender, and Hoplite thus has more flexibility to adapting data transfer schedule. For reduce, we need to make sure all the objects are reduced once and only once: when one object is added into a partial reduce result, the object should not be added into any other partial results.
Assume $n$ objects. Without the support of collective communication in task-based distributed systems, each node sends the object to a single receiver. network latency is $L$ , network bandwidth is $B$, and the object size is $S$. Total reduce time : $L+ \frac{nS}{B}$ . 为了缓解receiver作为唯一root的带宽瓶颈,考虑$d-nary$ tree, the total running time is $L+log_{d}n+ \frac{nS}{B}$. It reduces the latency due to the bandwidth constraint but incurs additional latency because the height of the tree grows to $log_{d}n$. The optimal choice of $d$ depends on the network characteristics, the size of the object, and the number of participants.
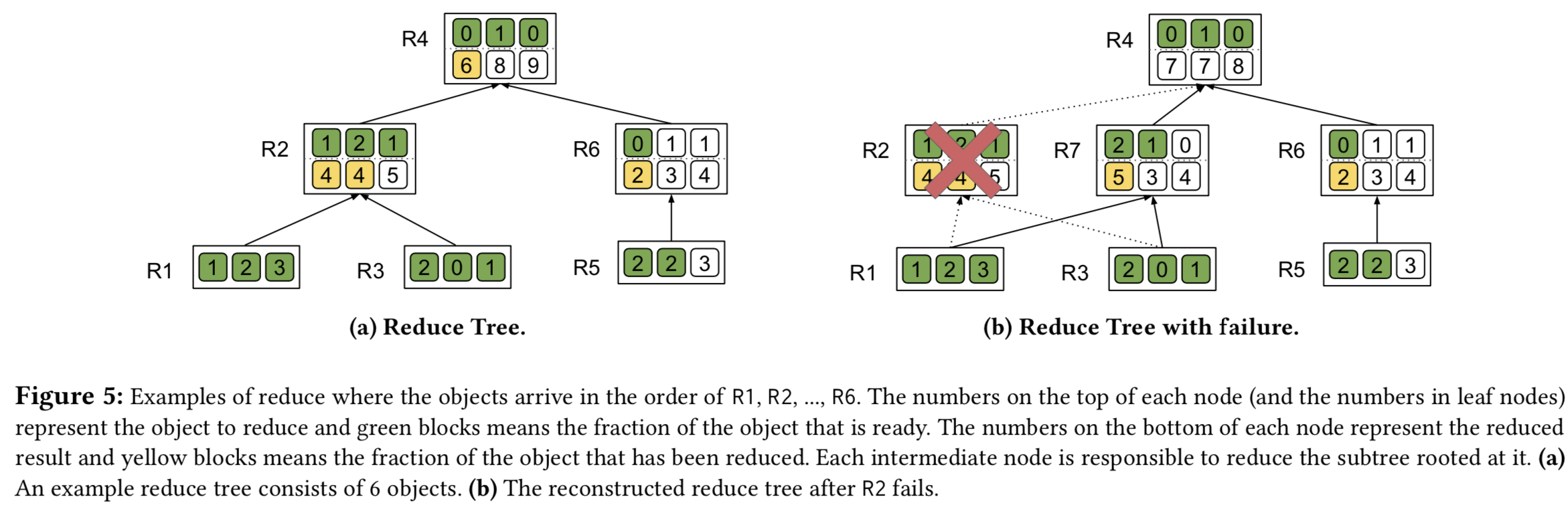
Fault-Tolerant Collective Communication
也是分的broadcast和reduce讨论
Implementation
Python front end
object directory service: gRPC
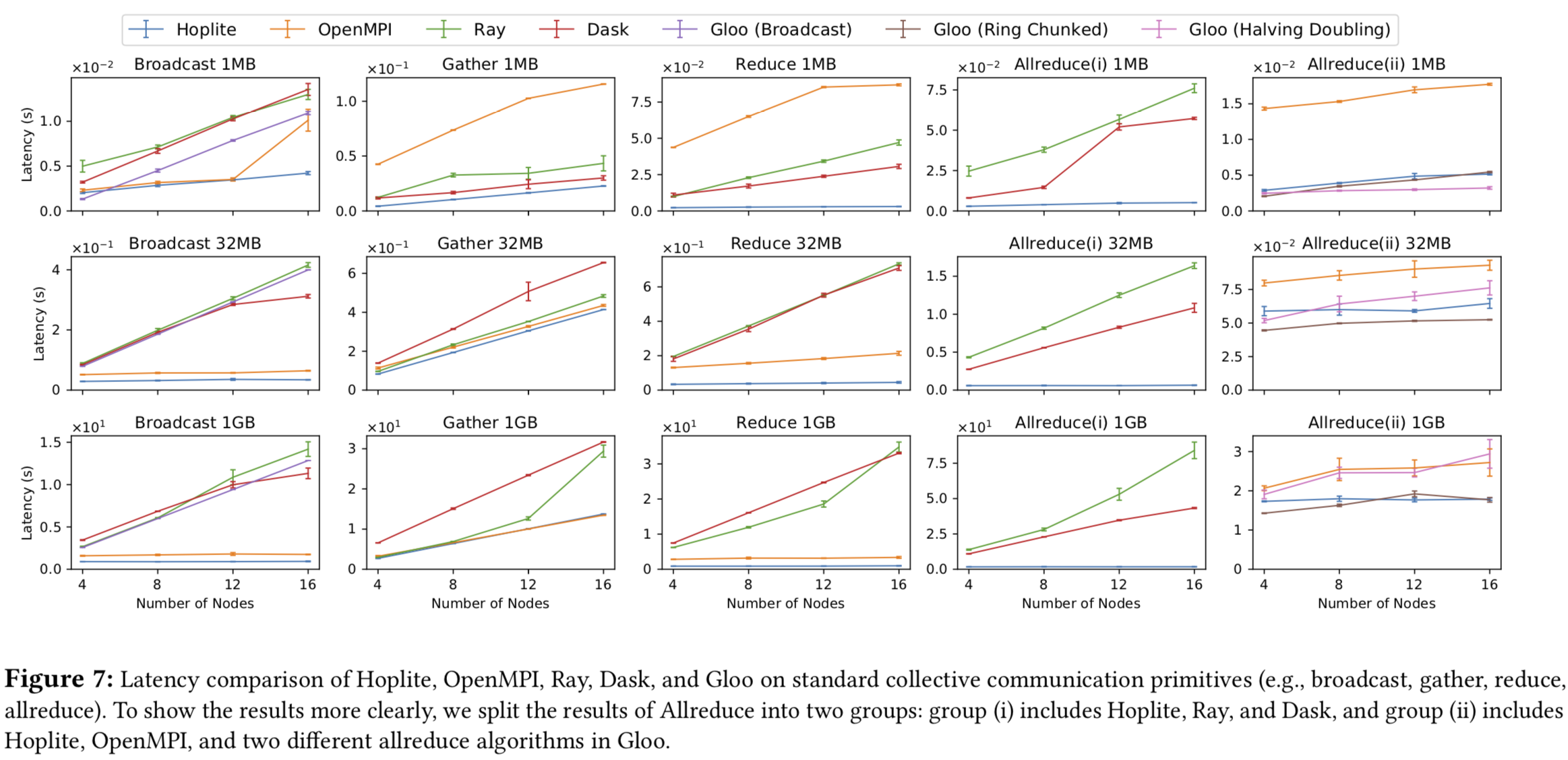
Evaluation
Thinking
非常典型的系统设计文章。注意思考为什么引入各个design。
几个问题(参考Public Review): the current design of Hoplite assumes that the network bandwidth between all the nodes is uniform, which may not hold in production environments where the available bandwidth across the network is dynamic and heterogeneous, so how to accommodate such heterogeneity? Furthermore, Hoplite does not support pipelining into GPU memory in its current design. So if training with GPU, the application has to copy data between GPU and CPU memories, then how to extend the fine-grained pipelining into GPU memory?
参考文献
Hoplite: Efficient and Fault-Tolerant Collective Communication for Task-Based Distributed Systems