核心思想
在可编程交换机数据平面实现时间同步协议. 亮点:非常详尽的可编程交换机各部分delay的测量
Motivation
- NTP (Network time protocol) 精度不够(软件timestamp)
- PTP标准 (IEEE 1588 Precise Time Protocol)精度高,能够实现纳秒级别的同步(硬件timestamp),但是由于通常由端主机软件或者交换机控制平面实现,存在一些问题:(1)the client requires several synchronization rounds and statistical filtering to offset clock drifts suffered during software processing delays. This results in clients requiring up to 10 minutes to achieve an offset below 1 µs.(2)在高负载情况下精度下降至100微秒(3)软件实现不易扩展(性能下降),专有硬件设备部署开销大
-
DTP (Datacenter Time Protocol) 利用物理层clock(Ethernet PHY layer)同步机制。(1) 非常依赖物理层特性:For 10 Gbps link speed, the PHY frequency is 156.25 MHz, and thus a single clock cycle is 6.4 ns. The synchronization precision achievable for 10G NIC is bounded by 25.6 ns (4 clock cycles) for a single hop. (2)全部物理层需要部署特殊硬件
- 可编程交换机带来的机遇: (1)灵活的数据包头处理; (2) 带状态存储;(3)自带ns级时钟, 使用42-48 bit counters保证能够几小时不回绕;
Measurement and understanding
设计前的重要一步:需要理解 参考时钟 与 请求的client的通信中各部分的delay组成及变化。 Achieving nanosecond-scale synchronization requires accounting for nanosecond-level variability in the various delay components
模型:request-respond— a client sends a request to synchronize with a server who maintains the reference clock
PISA:
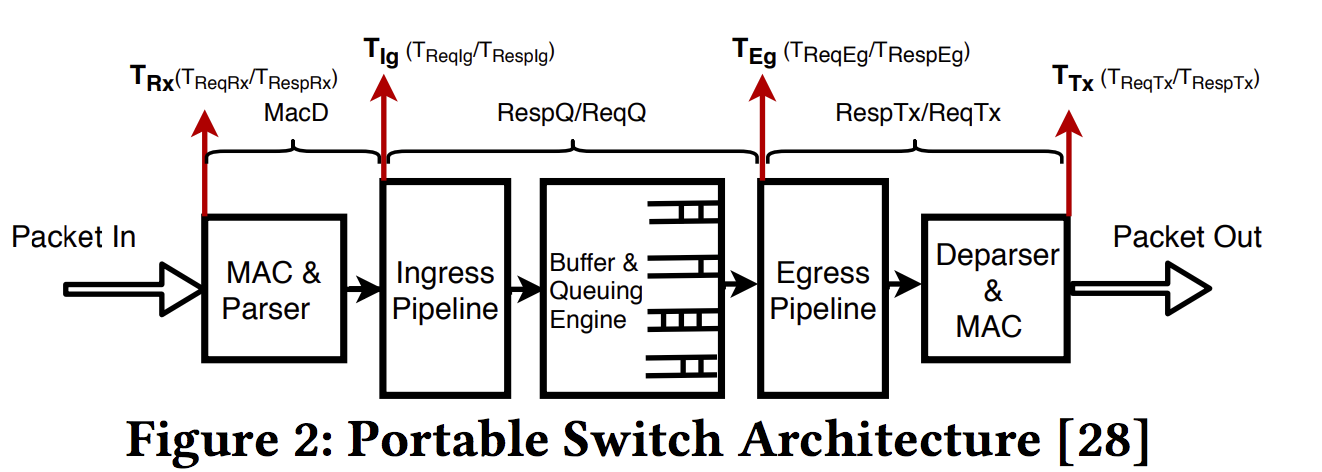
Switch to Switch
Delay breakdown:
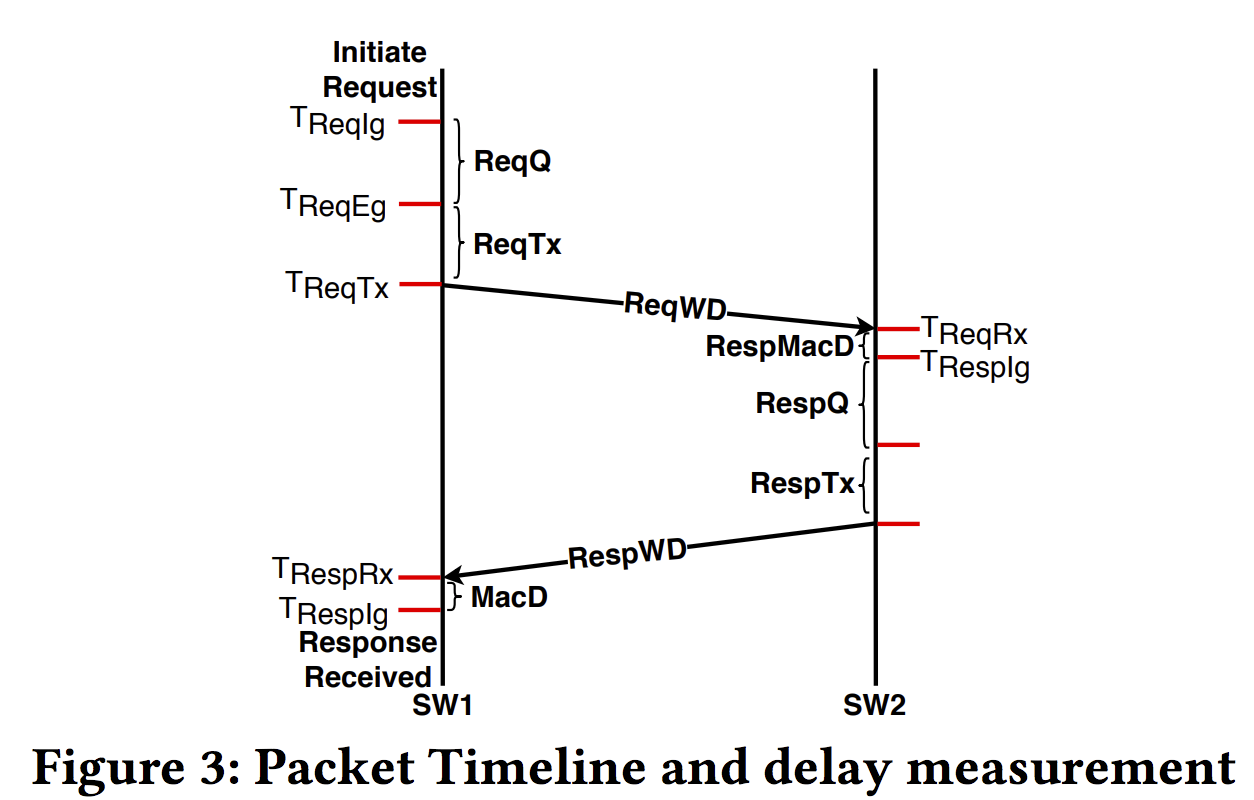
$T_{ReqIg}$: Timestamp (Request packet arrival at ingress pipeline of SW1).
ReqQ: Duration (Ingress pipeline processing and packet queuing at buffer engine).
ReqWD: Duration (Wire-delay across DAC cable).
MacD: Duration (Input buffering and parsing).
其余可结合 Figure 2. 通过加timestamp, 论文进行了重复实验测量每个delay component.
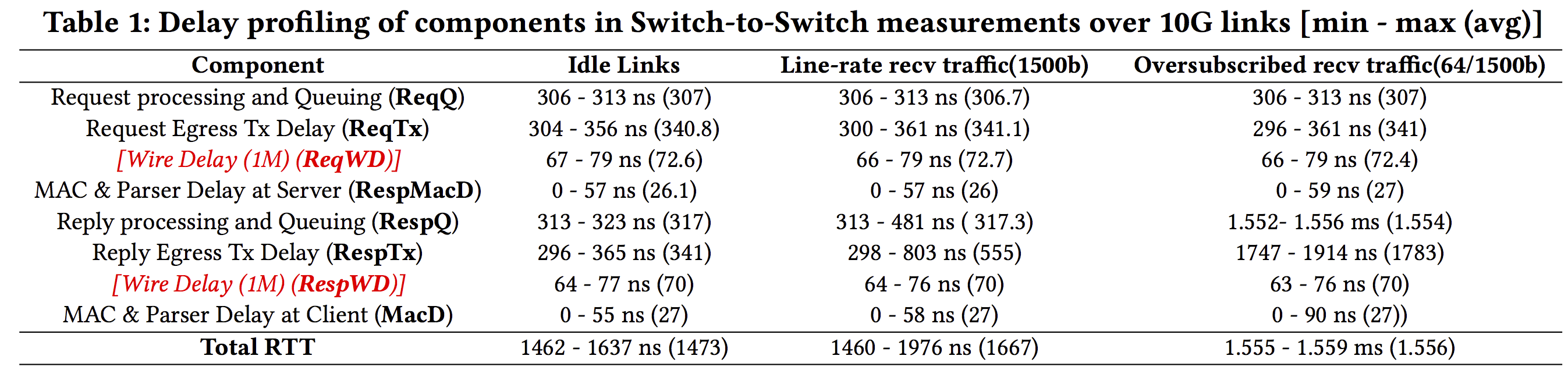
重要结论:
(1) RespTx and RespQ to be the major contributors of the total delay; RespTx includes egress pipeline processing, deparsing, Tx MAC delay and serialization,其中 egress pipeline processing时间固定,变量来自于其他三个
(2) Wire-delay具有不对称性:between request and response 并且asymmetry variation随着链路速率增加而降低(也就是链路速度越高时钟精度越高)
(3) 尽管不同component的delay会变化, 但是它们中的大多数都是可测量的, 这种变化性不会影响时钟同步, 唯一unaccounted的是wire delay.
(4) To accurately account for a packet’s exit timestamp, a follow-up packet is required. The follow-up packet could be avoided if the packet departure timestamp could precisely capture packet’s exit time and could be embedded in the data-plane.
Switch to Host
A request packet originates from a host (rack server) and a switch responds to the request. 使用了两种网卡。其中一种网卡:

NicWireDelay: consists of the two-way wire delay and the MAC/serialization delay incurred at the NIC/transceiver.
重要结论:
(1) An unaccounted and variable : NicWireDelay.
(2) The NicWireDelay varies up to 27 ns in Intel X710 (SFP+) and 16 ns in Intel XXV710 (SFP28) under idle conditions.
(3) 当有主机的cross traffic存在时, NicWireDelay增加. 几乎随load线性增加. traffic packet 64bytes比 1500 bytes增加更快.
(4) 主机需要知道cross traffic的volume: 时间同步在有主机的upstream cross traffic 存在时会产生错误,由于(asymmetry of NicWireDelay).
Design
时间同步的工作流程:首先网络中的一个交换机被指定为 master switch; 网络中的交换机与master switch (directly or indirectly) 通信获得全局时间.由于存在时钟漂移, 上述通信需要定期执行. 网络中的交换机同步后, 主机可直接向交换机查询进行同步.
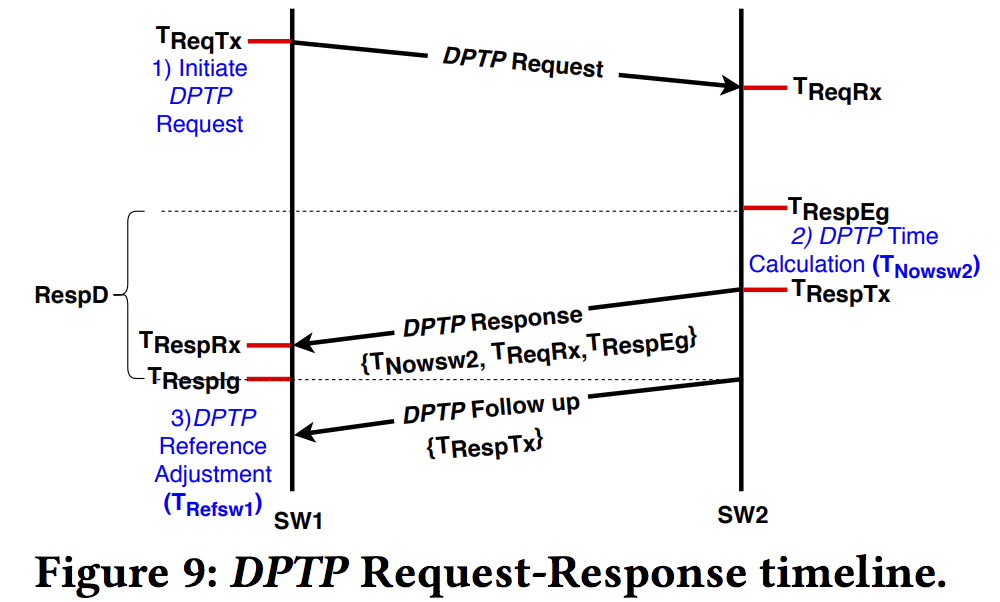
Clock Maintenance The master switch SW stores the reference clock timestamp from an external global clock source to the data-plane ASIC as $T_{Ref_{SW}}$ and stores the current data-plane timestamp ($T_{RespIg}$) to a register $T_{offset}$.
Era Maintenance 处理回绕. In order to scale the counter limit, the switch’s control-plane program probes the data-plane counter periodically to detect the wrap around. Upon detection, it increments a 64-bit era register $T_{era}$ by $2^x − 1$.
Switch Time-keeping Every time the switch SW receives DPTP queries from its child switch/host, it calculates $T_{Now_{SW}}$ using the current $T_{RespEg}$. (using $T_{RespEg}$ to avoid queuing delays)
\[T_{Now_{SW}} = T_{Ref_{SW}} + (T_{era} + T_{RespEg} - T_{offset})\]Switch to Switch
\[T_{Ref_{SW1}} = T_{Now_{SW2}} + RespD\] \[RespD = \frac{(T_{RespRx} −T_{ReqTx} ) − (T_{RespTx} −T_{ReqRx})}{2} + (T_{RespTx} −T_{RespEg}) + (T_{RespIg} −T_{RespRx} )\]follow-up packet负责携带$T_{RespTx}$
Host to Switch
ToR交换机需要维护从host收到traffic的rate.
Phase 1: Profiling. host初始化, host发送DPTP probe packet, 交换机同时回复rate, 同时维护$AvgNicWireDelay$. 如果rate接近0:
\[NicWireDelay = (T_{RespRx} −T_{ReqTx} ) − (T_{RespTx} −T_{ReqRx} )\]Phase 2: Synchronization. OWD是one-way $NicWireDelay$.
\[RespD = OWD + (T_{RespTx} −T_{RespEg})\] \[OWD=\left\{ \begin{aligned} \frac{NicWireDelay}{2} ;if R \approx 0 \\ \frac{AvgNicWireDelay}{2} ;Otherwise \end{aligned} \right.\]Implementation and evaluation
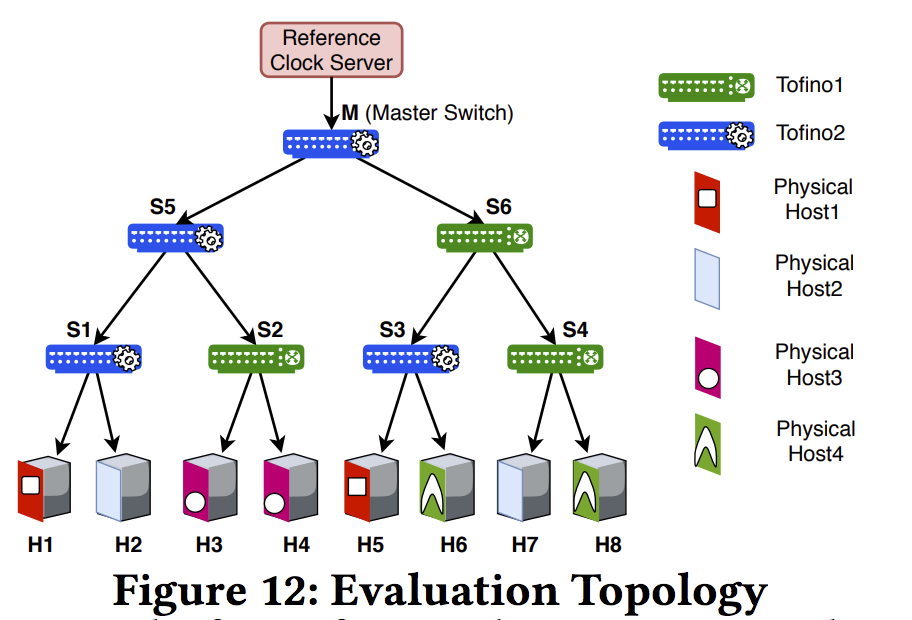
-
两台Tofino组成虚拟的拓扑
-
Follow-up handler: 在control plane实现. Each time a DPTP request is received, the Follow-up handler gets a learn digest from the data-plane with the following information: 1) host mac-address, 2) DPTP reply out-port. The handler then probes the port’s register for the transmit timestamp ($T_{RespTx}$), crafts a DPTP follow-up packet containing $T_{RespTx}$ destined to the host mac-address, and sends to the data-plane via PCIe.
-
分switch to switch 和 host to switch. 分别测量 一跳距离的交换机 两跳 三跳 四跳距离的交换机间的同步error follow up packets的 CPU消耗, 资源消耗(与switch.p4比), drift等
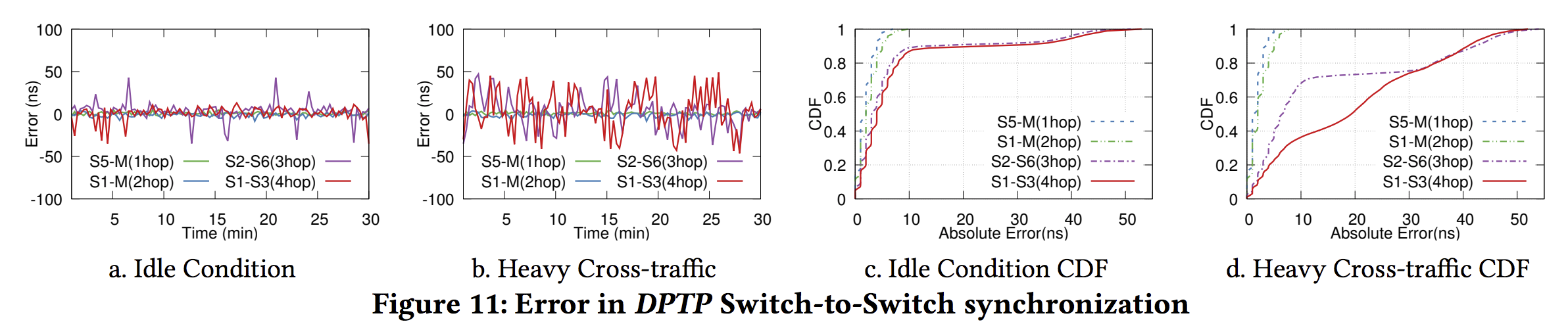
My thinking
参考文献
Precise Time-synchronization in the Data-Plane using Programmable Switching ASICs