核心思想
对已有dc transport 工作总结,结合各类方法的优势提出新的传输优化。
已有工作分类
(1)Self adjusting endpoints:发送端独立地根据自己探测到的网络状况调整速率,TCP,DCTCP等都属于此类。
网络拥塞状况通过拥塞信号获知,包括隐式的(丢包)和显式的(ECN)。当拥塞发生时,窗口会被减少,如果以追求公平性为目标,所有流的窗口都减相同的factor(TCP);如果以提供优先级的服务为目标,其他作为因素将决定factor大小,比如剩余流大小(L2TCP),deadline(D2TCP)。
优点:非常好的扩展性。易部署。
缺点:当需要考虑优先级时,这类方法达不到较优的效果(相比pFabric、PDQ).原因在于这种方式永远不可能提供严格的优先级。即使是最低优先级的流(本应当被pause)也会一个RTT至少发送一个数据包。当高负载有很多并发流的时候降低性能。
实验验证:比较DCTCP、D2TCP、pFabric从load 10%-90%下 deadline flow完成deadline的比例。高负载时(大约从30%开始)D2TCP就开始接近DCTCP了。
(2)Arbitration:显式速率控制,交换机(或控制器)追踪所有的网络流和其属性(deadline、size等)做调度决策。以PDQ为代表。
调度决策的输出是每个流的发送速率,0就代表pause,如果是full link capacity就代表是最高优先级可以占满带宽。已有的工作通过一种分布式的方法来实现:路径上的每个交换机计算速率,最终速率选择最小的。
优点:流的速率收敛快。能够实现严格优先级调度。
缺点:flow switching overhead。当瓶颈不在网络资源时,计算的速率不准确。
实验验证:比较PDQ与DCTCP从load 10%-90%下的AFCT。intra-rack, all to all 流量。高负载(70%)时,大量的流之间存在contention。flow switching overhead开始体现,在AFCT上甚至不如DCTCP。
(3)In-network prioritization:交换机根据数据包携带的优先级决定哪个数据包先调度(以及在拥塞的状况下先丢弃),以pFabric为代表。
pFabric实际上比较极端:只需要flow scheduling,不需要端rate control (rate control 非常简单)。
这种优先级方式有两个属性:work conservation(低优先级的数据包在没有高优先级数据包的情况下会得到调度)和preemption(高优先级数据包可以抢占当前被调度的低优先级数据包)。
优点:work conservation。flow switching overhead低 。
缺点:交换机队列数目有限。switch-local decision在多链路下并不是最优。switch-local decision的例子见下图:
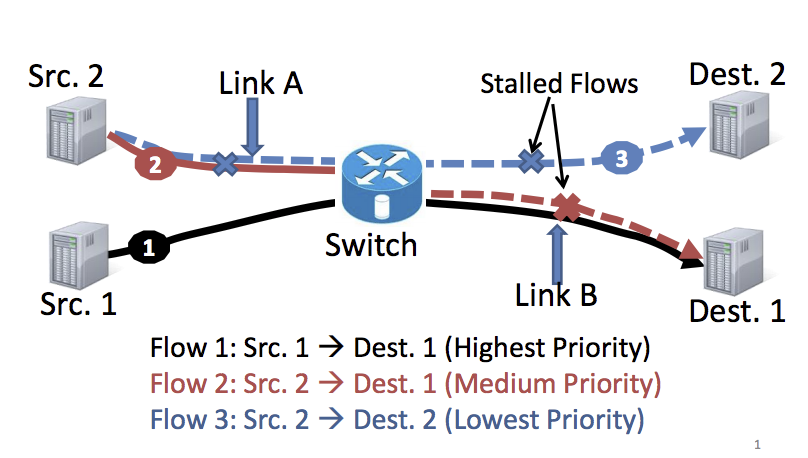 Flow 1 先占了带宽,因为flow 2 与 1 共享链路B, 所以阻塞了flow 2. Flow 3虽然没有与1 竞争,但是因为优先级低,因为与flow 2共享链路A,也被阻塞了。Flows 1 and 2 share link B, so only flow 1 can progress while flow 2 should wait. A protocol like pFabric continues to send packets of flow 2 on link A even though these packets are later dropped at link B. These unnecessary transmissions stall flow 3, which could have run in parallel with flow 1 as both flows do not share any link
Flow 1 先占了带宽,因为flow 2 与 1 共享链路B, 所以阻塞了flow 2. Flow 3虽然没有与1 竞争,但是因为优先级低,因为与flow 2共享链路A,也被阻塞了。Flows 1 and 2 share link B, so only flow 1 can progress while flow 2 should wait. A protocol like pFabric continues to send packets of flow 2 on link A even though these packets are later dropped at link B. These unnecessary transmissions stall flow 3, which could have run in parallel with flow 1 as both flows do not share any link
实验验证:测量pFabric在load增加时的丢包率,interaction between workers and aggregators within a single rack。当load 80%时,丢包率到达40%。These lost packets translate into loss of throughput as we could have used these transmissions for packets belonging to other flows.
三类策略可以相互补充
- In-network prioritization complementing arbitration: arbitration 重要的问题是flow switching overhead。PDQ假设网络无法提供区分服务,所以需要交换机显式为每个流计算速率,带来了通信开销和流切换可能的链路利用率低。通过借助In-network prioritization,arbitrator可以对flow赋予相对优先级。
- Arbitration aiding in-network prioritization: 网内优先级的方式,当许多流都被映射到同一高优先级队列中时,流的multiplexing导致性能下降(此时无法保证严格优先级)。As the number of flows is more than the number of queues, any static mapping of flows to queues will result in sub-optimal. performance。通过arbitration,可以将优先级进行动态映射,最高优先级的流被映射到最高一级队列中,其余映射到低一级队列中(这个其实就是One More Queue is Enough: Minimizing Flow Completion Time with Explicit Priority Notification的idea!!!!!!!!!!!!!!!!)。
- Arbitration aiding helping self-adjusting endpoints: 如果只有Arbitration,因为不能考虑到所有的bottleneck,计算的rate不准确,并且端即使能探测网络中的拥塞和空余带宽,也没有机会改变。借助于端的定期probe网络的功能,端能够自己探测网络中的剩余带宽,增加速率
PASE主要思想:结合运用,分别处理自己最擅长的部分
- Arbitrators should do inter-flow prioritization at coarse time-scales. They should not be responsible for computing precise rates or for doing fine-grained prioritization. —————————>对应PASE arbitration control plane的设计
- Endpoints should probe for any spare link capacity on their own, without involving any other entity. Further, given their lack of global information, they should not try to do inter-flow prioritization (protocols that do this have poor performance, as shown in Section 2). —————————>对应PASE endpoint rate control的设计
- In-network prioritization mechanism should focus on per-packet prioritization at short, sub-RTT timescales. The goal should be to obey the decisions made by the other two strategies while keeping the data plane simple and efficient.
PASE主要挑战
- arbitration control plane 低延时
-
降低计算开销
解决方法: early pruning和delegation两个优化
PASE其他细节设计
-
怎样在RTT时间粒度上enforce一个rate?
(1)For the flows mapped to the top queue, the congestion window is set to Rref × RTT in order to reflect the reference rate assigned by the arbitrator. (2) For all other flows, the congestion window is set to one packet. For the flows mapped to lower priority queues (except the bottom queue), the subsequent increase or decrease in congestion window cwnd is based on the well-studied control laws of DCTCP
-
对于低优先级的流,当超时发生后,怎样区分是因为优先级高的流多而长时间得不到调度,还是丢包?
论文的做法是当低优先级队列里的流发生超时后,使用小的probe数据包,发送一次,有两种情况:(1)收到对这个probe包的ACK———>说明之前超时是因为丢包;(2)也被delay了,没收到ACK,———>说明之前超时是因为优先级低排队,将低优先级的队列的超时时间设长一点,再发送probe。 当然还有种做法是在一开始根据队列的不同设置不同的超时时间,高优先级超时时间短,低优先级超时时间长。
-
如何处理因为调高优先级带来的乱序?
需要确保当一个流的提高到高优先级的队列中时,必须等待所有已经发送了的数据的ACK全部到达
My thinking
Coflow的scheduling与flow scheduling研究相同,也可以按照这三类分类。
-
Self adjusting endpoints
目前没有这类工作。难点在于一个coflow的endpoints有多对而且是不确定的,而一个flow的endpoints只有一对。coflow本身打破了self adjusting
-
Arbitration
集中式:
Varys The first one.
Aalo 解决需要提前知道size的问题
CODA 解决coflow识别问题
Sincronia 解决对rate control的依赖
分布式:
-
In-network prioritization
参考文献
Friends, not Foes – Synthesizing Existing Transport Strategies for Data Center Networks