核心思想
机器学习算法预测流的size, 除此之外的亮点:探讨了对流大小是不是知道的越多越好?
获取流大小 方法总结
-
应用提供
局限:有的应用一开始不知道大小;需要改应用API,对public cloud不适用
-
Flow aging (LAS PIAS)
局限:不适用于需要知道流确切大小的调度场景(fastpass、sincronia等);有效性与流分布特征有关 比如重尾分布还是效果不错的 但是当大部分流大小都相同时(轻尾分布)不好
-
根据TCP buffer的占用情况
局限:buffering只有当发送方瓶颈在网络或者接收方是才能反映流大小
-
监测系统调用
write send系统调用。大多数应用有标准的系统调用长度(Tomcat 8KB, MySQL 16KB, Spark standalone 100KB,YARN 262KB)。如果小于8KB,一次系统调用就可以完成,会体现出真实size大小
局限:只有当流小于一次标准系统调用的长度时,获取的信息才是准确的。可以根据这个获取小流大小!
-
从以前的trace中学习(机器学习)
局限:从以前的trace学习的重要依据是:很多job在数据中心中是重复的, one-shot的job则不适用
论文搭建了一个真实的机器学习系统(Flux)去预测。
选择适合的机器学习方法:Recurrent Neural Network with LSTM layers、Gradient Boosting Decisions Trees、Feed-Forward Neural Network
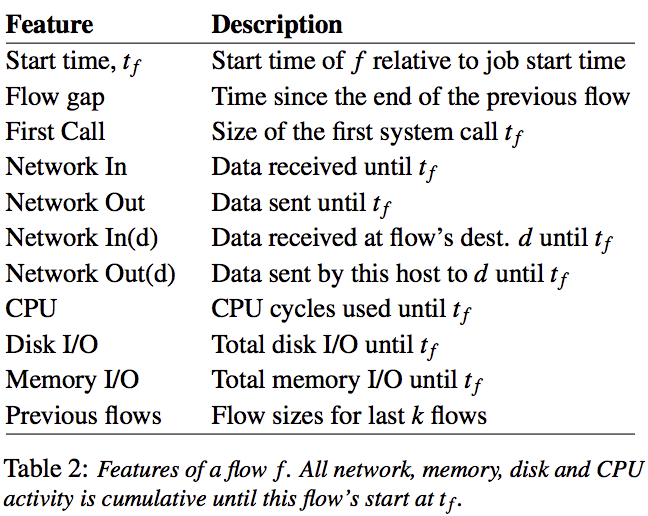
最终GBDT准确度最高,还对模型准确性、model大小、训练集大小 实现(offload)进行了讨论
使用这个预测模型,对网络流调度的进行了实验(simulatior:YAPS)FCT CCT
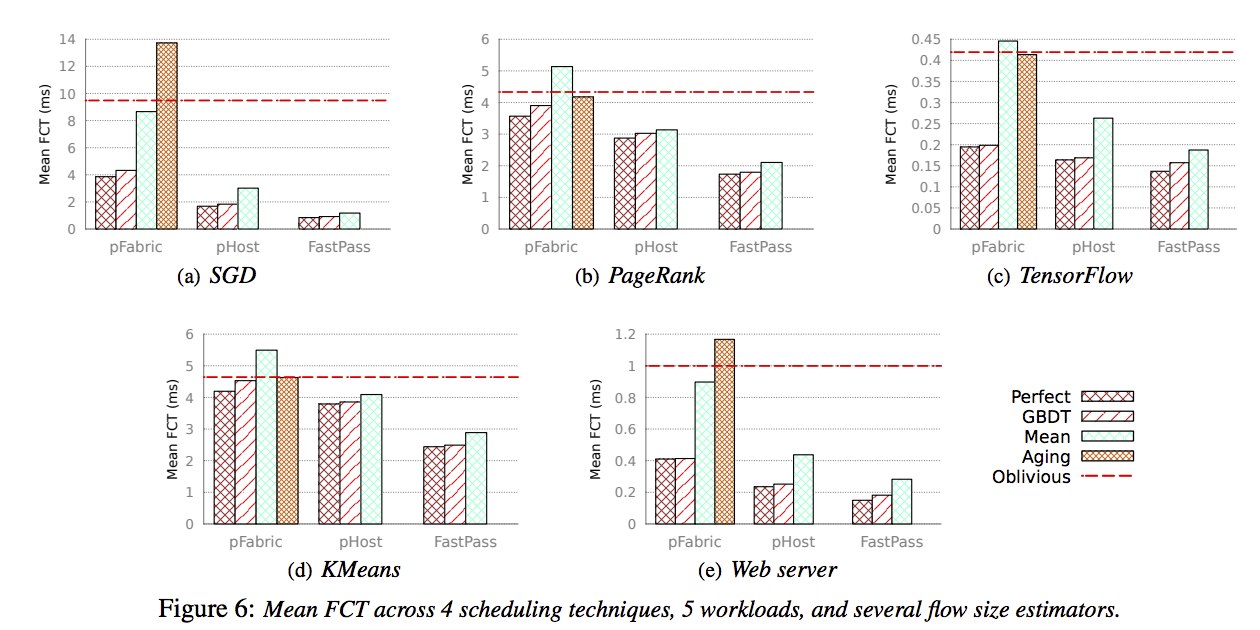
More knowledge—>better performance?
- 实验证明 Knowing x% of all flows 越多越好
- 实验证明 Knowing all flows of size up to x bytes: SRF-age 知道更大的流的size更有好处 因为这样大流就不用一开始与小流竞争了
- 针对Coflow scheduling: 发现有意思的结论: 知道更多coflow的大小有时反而会使CCT性能下降 论文进行了举例说明
-
Mean completion time across all co/flows
重要结论 SRF-age, making a certain flow’s size known can never deteriorate its performance, at least when interpreted in a worst-case manner